Fonting with GANs
1/30/2024
During my virtual residency at the Recurse Center, one of my goals was to get comfortable with PyTorch and Jupyter notebooks. Another was to build some highly responsive UI around machine learning. I've always liked David Ha's formulation that resource constraints are behind cognition's best tricks, and I hadn't seen a lot of inference executing in the browser. What kind of UI is possible with small models and no perceptible delay?
My first stab in this direction was an in-browser Generative Adversarial Net with the EMNIST handwriting dataset. And, putting the prize up front, here it is, running fast enough animate latent-space-interpolation in real time:
You can find the code for the Python side of this project here: VGAN-EMNIST Inversion. Big picture, this involved:
- training on a fast desktop with a Jupyter notebook
- finding ideal inputs for all 62 alphanumeric characters, a process called inversion
- exporting the trained network for ONNX Runtime
- some math for smoothly interpolating between inputs
Unlike most diffusion networks, GANs produce images in a single fast feedforward step, and their output makes up a smooth and structured latent space. This is why I thought they might be fast enough for animation, and their animation would be formally compelling.
I used Diego Gomez's Vanilla GAN in PyTorch as a starting point and swapped the MNIST (numeric) dataset for EMNIST (alphanumeric).
My training results were pretty weird, without a lot of recognizable characters. I visualized the first batch of training data:

It's hard to see what's going on unless you know what to look for, but TorchVision's EMNIST data is mirrored and rotated -90 degrees. Two extra transforms set things right:
compose = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([0.5], [0.5]), # rotate all images -90deg counter-clockwise transforms.RandomRotation((-90,-90)), # horizontal flip all images (probability = 1) transforms.RandomHorizontalFlip(p=1), ])
Everything worked as expected after that, and 200 training epochs later, the network was making familiar shapes. Because I wasn't using labeled data, these random samples show a handful of hybrid weirdos, but they seemed oriented correctly.
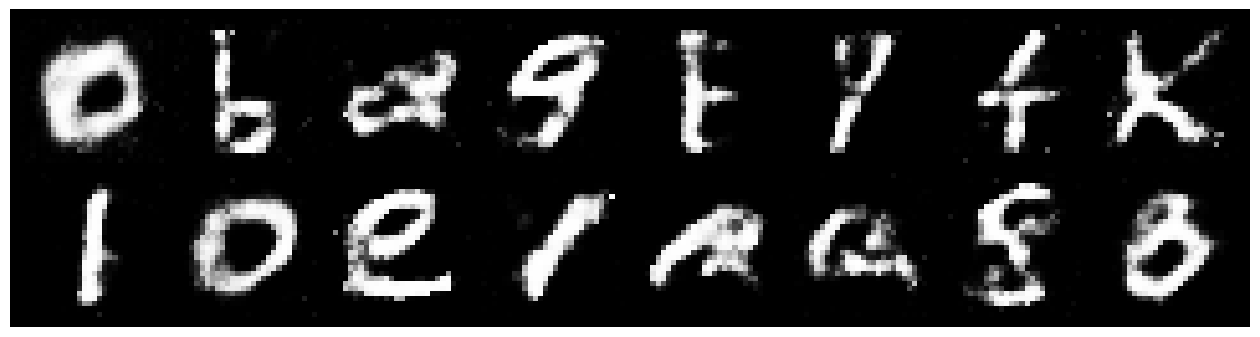
The Map
To render an actual letter repeatably, I'd need to find a nice version generated by the network and note the 100-value input that created it (or its coordinates in this particular 100-dimensional image-space). Here's one:
[ -1.0, -1.0, 1.0, -0.0486, -1.0, 0.9989, -1.0, -0.1445, -0.3458, 1.0, 1.0, -1.0, 1.0, 1.0, -1.0, -0.3575, 1.0, -1.0, 0.7807, -1.0, -1.0, -1.0, 1.0, 1.0, 1.0, 0.1007, -1.0, 1.0, -0.9726, -1.0, 1.0, -1.0, -0.9486, 1.0, 0.2914, 1.0, -1.0, 1.0, -1.0, -1.0, -1.0, 0.1367, -0.9471, 0.2176, 1.0, -1.0, 0.6586, 0.8326, -0.7876, -1.0, -0.3623, 0.5928, 0.7861, 1.0, 0.546, -1.0, -1.0, 0.4815, 1.0, -1.0, 1.0, 1.0, 0.3592, 1.0, -0.0093, -1.0, -1.0, -1.0, 0.8022, 0.8678, -1.0, -1.0, -1.0, -1.0, 1.0, -1.0, 0.9368, 0.983, 0.9562, 0.6253, -0.5211, -1.0, -1.0, -1.0, 1.0, 1.0, -0.2063, -0.1222, 0.9239, 0.4377, -1.0, 1.0, -1.0, -1.0, -1.0, -0.3888, 0.7914, -0.6846, -0.9638, 1.0, ]
I gathered these manually for a while by randomly sampling, then copy-pasting the input for any well-formed character. This got ineffective really quickly as I filled out my collection, and it became clear that I needed to automate.
Inversion
I credit Fast.ai's great explanation of SGD for making this thinkable: For each character, I'd take a single real example from the labeled data and gradient-descend through the latent space for a similar fake image. This is possible because we can treat the input/coordinates of an image just like we treat model weights during training: feedforward through the network, determine the error between the output and the real image, and backpropagate up to the input to learn how it should change. My search function ended up looking something like this:
def inversion_search(target_img, generator, steps=100, rate=0.01): input = torch.zeros(100).requires_grad_() for i in range(steps): loss = emnist_gan_mse(input, target_img, generator) loss.backward() with torch.no_grad(): for j in range(len(input)): input[j] = torch.clamp(input[j] - input.grad[j] * rate, -1, 1) return input
A silly bug almost made me give up on this: I had the inversion search working on the pre-transform data, so it was still mirrored and rotated. Amazing how hard this was to see when I wasn't looking for it, even having dealt with it earlier. I had to plot the whole grid of targets before I spotted it, and it hammered home the value of easy fluency with matplotlib.
Anyway, here's the working search, animated in order to convey a fraction of my dawning joy when I fixed the bug. Some characters are much slower to home in than others, like the capital "B". You can almost feel it rolling down different slopes as it finds its way.

Packaging for the Frontend
With a map to every character I'd want to render, it was time to bring the generator network into the browser. Torch.onnx needs to actually run the model to export it, so I provided an input, then names for the data going in and out, which became object keys in JavaScript. I also exported the map to a JSON file.
torch.onnx.export( # network with desired weights loaded generator, # properly shaped random input torch.randn(1, 100), # output filename "vgan_emnist.onnx", # JS object keys input_names=["z"], output_names=["img"], verbose=False, export_params=True, )
The sandbox at the top of this writeup uses onnxruntime-web to run the exported network. Its character map is a combination of the best images from several runs of the inversion search, saved in addresses.json.